Cerebras AI Model Studio
Train GPT-Style Models 8x Faster
Than Traditional Clouds at a
Fraction of the Cost
Hosted on the Cerebras Cloud @ Cirrascale, the Cerebras AI Model Studio enables
customers to train state-of-the-art Generative Pre-trained Transformer (GPT) models
on the revolutionary Cerebras CS-2 accelerator.
The Cerebras AI Model Studio
The Cerebras AI Model Studio is a simple pay by the model computing service powered by dedicated clusters of Cerebras CS-2’s and hosted by Cirrascale Cloud Services. It is a purpose-built platform, optimized for training large language models on dedicated clusters of millions of cores. It provides deterministic performance, requires no distributed computing headaches, and is push-button simple to start.
The Problem
Training large Transformer models such as GPT and T5 on traditional cloud platforms can be painful, expensive, and time consuming. Gaining access to large instances typically offered in the cloud can often takes weeks just to get access. Networking, storage, and compute can cost extra, and setting up the environment is no joke. Models with tens of billions of parameters end up taking weeks to get going and months to train.
If you want to train in less time, you can attempt to reserve additional instances – but unpredictable inter-instance latency, makes distributing AI work difficult, and achieving high performance across multiple instances challenging .
Our Solution
The Cerebras AI Model Studio makes training large Transformer models fast, easy, and affordable. With Cerebras, you have millions of cores, predictable performance, no parallel distribution headaches – all of this enables you to quickly and easily run existing models on your data or to build new models from scratch optimized for your business.
A dedicated cloud-based cluster powered by Cerebras CS-2 systems with millions of AI cores for large language models and generative AI:
- Train 1-175 billion parameter models quickly and easily
- No parallel distribution pain: single-keystroke scaling over millions of cores
- Zero DevOps or firewall pain: simply SSH in and go
- Push-button performance: models in standard PyTorch or TensorFlow
- Flexibility: pre-train or fine-tune models with your data
- Train in a known amount of time, for a fixed fee
Discover the Benefits of the Cerebras AI Model Studio
Train Large Models in Less Time
- Train 1-175 billion parameter models 8x faster than the largest publicly available AWS GPU instance
- Enable higher performing models with our longer sequence lengths (up to 50,000!)
Ease of Use
- Easy access: simply SSH in and go
- Simple programming: range of large language models in standard PyTorch and TensorFlow
- Push-button performance: the power of millions of AI cores dedicated to your work with no distributed programming required
- Even the largest GPT models run without a single minute spent on parallelizing work
Price
- Models trained at half the price of AWS
- Predictable fixed price cost for production model training
Flexibility
- Train your models from scratch or fine-tune open-source models with your data
Ownership
- Dependency free - keep the trained weights for the models you build
Simple & Secure Cloud Operations
- Simple onboarding: no DevOps required
- Software environment, libraries, secure storage, networking configured and ready to go
Should You Fine-Tune or Train from Scratch?
Ultimately the decision to fine-tune a pre-trained model or to train a model from scratch depends on various factors such as the size of the dataset, the similarity between the pre-trained model's task and the new task, the availability of necessary computational resources (we got you covered there), and overall time constraints. To make it as easy as possible, Cerebras developed the flow chart to the right to help guide you.
If you have a small dataset, fine-tuning a pre-trained model can be a good option. In fine-tuning, you take a pre-trained model and retrain it on a new dataset specific to your task. This approach can save you time since the pre-trained model has already learned general features from a large dataset. Fine-tuning can also help to avoid overfitting on small datasets.
However, if you have a large dataset, training a model from scratch may be a better option. Training a model from scratch allows you to have more control over the architecture, hyperparameters, and optimization strategy, which can lead to better performance on the specific task. Additionally, if the pre-trained model's task is significantly different from your task, fine-tuning may not be as effective.
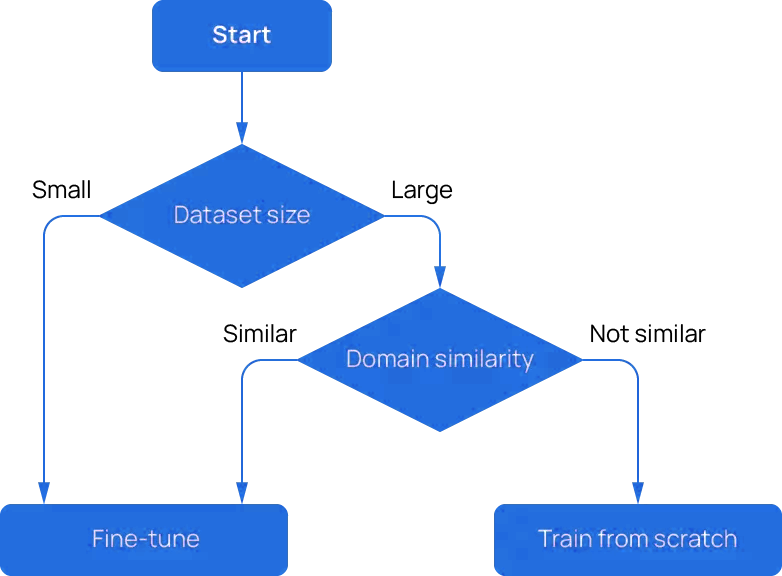
1. Dataset size is dependent upon the model architecture used for training and the task. If you are unsure, our world-class engineers will be happy to help
2. Domain similarity assess if the data used to pre-train a generic model and your data are similar enough such that your fine-tuned model will perform well on downstream tasks
Fine-Tuning
Standard Offering
The Fine-Tuning Standard Offering is a self-service process, similar to the Training from Scratch Standard Offering. Pricing is based per 1,000 tokens so there's no surprises. Minimum spend is $10,000.
White-Glove Support with Cerebras Experts
With White-Glove Support, Cerebras thought leaders will fine-tune a model on the Cerebras Wafer-Scale Cluster on your behalf and will deliver you trained weights. Contact us directly for pricing.
Fine-Tuning - Standard Offering Pricing
Introductory pricing below. These prices represent blocks of dedicated cluster time for the chosen model. Additional system time is available at an hourly rate as needed.
| Model | Parameters | Fine-tuning price per 1K tokens | Fine-tuning price per example (MSL 2048) | Fine-tuning price per example (MSL 4096) | Cerebras time to 10B tokens (h)** | AWS p4d (8xA100) time to 10B tokens (h) | Ready to Start |
|---|---|---|---|---|---|---|---|
| Eleuther GPT-J | 6 | $0.00055 | $0.0011 | $0.0023 | 17 | 132 | Sign-Up |
| Eleuther GPT-NeoX | 20 | $0.00190 | $0.0039 | $0.0078 | 56 | 451 | Sign-Up |
| CodeGen* 350M | 0.35 | $0.00003 | $0.00006 | $0.00013 | 1 | 8 | Sign-Up |
| CodeGen* 2.7B | 2.7 | $0.00026 | $0.0005 | $0.0027 | 8 | 61 | Sign-Up |
| CodeGen* 6.1B | 6.1 | $0.00065 | $0.0013 | $0.0030 | 19 | 154 | Sign-Up |
| CodeGen* 16.1B | 16.1 | $0.00147 | $0.0030 | $0.011 | 44 | 350 | Sign-Up |
* T5 tokens to train from the original T5 paper. Chinchilla scaling laws not applicable.
** Note that GPT-J was pre-trained on ~400B tokens. Fine-tuning jobs can employ a wide range of dataset sizes, but often use order 1-10% of the pre-training tokens. As such, one might fine-tune a model like GPT-J with ~4-40B tokens. We provide estimated wall clock time to fine-tune train the model checkpoints above with 10B tokens on Cerebras AI Model Studio and an AWS p4d instance in the table above to give you a sense of how much time jobs of this scale could take.
Train From Scratch
Standard Paid Access
Train your own state-of-the-art GPT model for your application on your data. The process is simple:
- Pick a large model from the list below (or contact us for custom projects)
- See the price, time to train: no surprises
- SSH in and get going
- Enjoy secure, dedicated access to programming environment for the training period
- Cerebras model implementation for the chosen model appear
- Systems, code examples, documentation are at your fingertips
- Scripts allow the user to vary training parameters, e.g. batch, learning rate, training steps, checkpointing frequency
- Use Cerebras-curated Pile dataset to train upon, if desired
- Save and export trained weights and training log data from your work to use as you see fit
Additional Services Available
Cirrascale and Cerebras provides additional services as needed, such as:
- Bigger dedicated clusters to are available to reduce time to accuracy and work on larger models
- Additional cluster time for hyperparameter tuning, pre-production training runs, post-production continuous pre-training or fine-tuning is available by the hour
- CPU hours from Cirrascale for dataset preparation
- CPU or GPU support from Cirrascale for production model inference

Fixed-Price Production Model Training
Introductory pricing below. These prices represent blocks of dedicated cluster time for the chosen model. Additional system time is available at an hourly rate as needed.
| Model | Parameters | Tokens to Train to Chinchilla Point (B) | Cerebras AI Model Studio CS-2 Days to Train | Cerebras AI Model Studio Price to Train | Ready to Start |
|---|---|---|---|---|---|
| GPT3-XL | 1.3 | 26 | 0.4 | $2,500 | Sign-Up |
| GPT-J | 6 | 120 | 8 | $45,000 | Sign-Up |
| GPT-3 6.7B | 6.7 | 134 | 11 | $40,000 | Sign-Up |
| T-5 11B | 11 | 34* | 9 | $60,000 | Sign-Up |
| GPT-3 13B | 13 | 260 | 39 | $150,000 | Sign-Up |
| GPT NeoX | 20 | 400 | 47 | $525,000 | Sign-Up |
| GPT 70B | 70 | 1,400 | Contact For Quote | Contact For Quote | Contact For Quote |
| GPT 175B | 175 | 3,500 | Contact For Quote | Contact For Quote | Contact For Quote |
* T5 tokens to train from the original T5 paper. Chinchilla scaling laws not applicable.
** Expected number of days, based on training experience to date, using a 4-node Cerebras Wafer-Scale Cluster. Actual training of model may take more or less time.
Interested? Sign Up for a Free Trial
Sometimes it makes sense to try before you buy. We offer free trials to qualified companies looking seriously at the Cerebras Cloud. Our free trial enables you to familiarize yourself with Cerebras’ simple programming model based on Python and standard ML frameworks PyTorch and TensorFlow. You'll be able to experience push-button model scaling from 1-20B parameters.
The 2-Day Free Trial includes the ability to run models with several model implementations to review and choose from. You'll also have a curated Pile dataset to train upon while in a secure, dedicated access to the programming environment. We provide technical documentation and training guides to help you get started. It's easy, so sign up to try the Cerebras AI Model Studio today.
Sign-Up for Free TrialReady to use Cerebras AI Model Studio?
Ready to take advantage of our flat-rate monthly billing, no ingress/egress data fees, and fast multi-tiered storage with Cerebras Cloud?
Sign Up and Get Started with the Cerebras AI Model Studio
If you are interested in using the Cerebras AI Model Studio, part of the Cerebras Cloud @ Cirrascale, please fill out our sign-up form. Please completely fill out the form so that we can ensure an accurate review of your request.
Once received, we'll review you information and have one of our onboarding representatives give you a call to schedule your service.