
Introducing Bow: The Next IPU
Get access to the Graphcloud, utilizing Graphcore's new 3rd generation systems based on the world’s first 3D Wafer-on-Wafer processor. The Bow IPU delivers a huge power and efficiency boost, enabling significant performance improvements for real-world AI applications.
Graphcore's Next Generation 3D Wafer-on-Wafer IPU Systems are Here
Graphcore now offers the world’s first 3D Wafer-on-Wafer processor, the Bow IPU. The Bow IPU is the first processor in the world to be manufactured using a revolutionary Wafer-on-Wafer (WoW) silicon production technology. This technology enables much more efficient power delivery, higher operating frequency and enhanced overall performance. Graphcore's next generation Bow Pod systems deliver up to 40% higher performance and 16% better power efficiency for real-world AI applications – all for the same price and with no changes to existing software.
Graphcore systems excel at both training and inference. The highly parallel computational resources together with graph software tools and libraries, allows researchers to explore machine intelligence across a much broader front than current solutions. Graphcore technology allows recent successes in deep learning to be effectively and efficiently applied towards algorithms developed for general artificial intelligence, NLP, financial risk analysis and more.
Graphcloud enables customers to use various Bow Pod and IPU-POD Classic configurations as a service for a unique solution for massive, disaggregated scale-out enabling high-performance machine intelligence compute to supercomputing scale. The latest Graphcore Bow Pod configurations build upon the innovative Bow-2000 and offers seamless scale-out to work as one integral whole or as independent subdivided partitions to handle multiple workloads and different users.
Slurm and Kubernetes support makes it simple to automate application deployment, scaling, and management of Bow Pods. Virtual-IPU™ technology offers secure multi-tenancy. Developers can build model replicas within and across multiple Bow Pods and provision IPUs across many Bow Pods for very large models. Innovators can focus on deploying their AI workloads at scale, using familiar tools while benefitting from cutting-edge performance in the cloud.
Performance Results
Review the latest detailed Bow IPU training and inference performance results.
VIEW RESULTSDownload Our eBook
Read our eBook to discover the main benefits to using Graphcore in the public cloud.
REQUEST YOUR eBOOKFull Software Stack and Framework Support
With Poplar, managing IPUs at scale is as simple as programming a single device, allowing you to focus on the data and the results. Graphcore's state of the art compiler simplifies IPU programming by handling all the scheduling and work partitioning of large models, including memory control, while the Graph Engine builds the runtime to execute your workload efficiently in Graphcloud. Graphcore has made it possible to dynamically share your AI compute, with Graphcore’s Virtual IPU software. You can have tens, hundreds, even thousands of IPUs working together on model training.
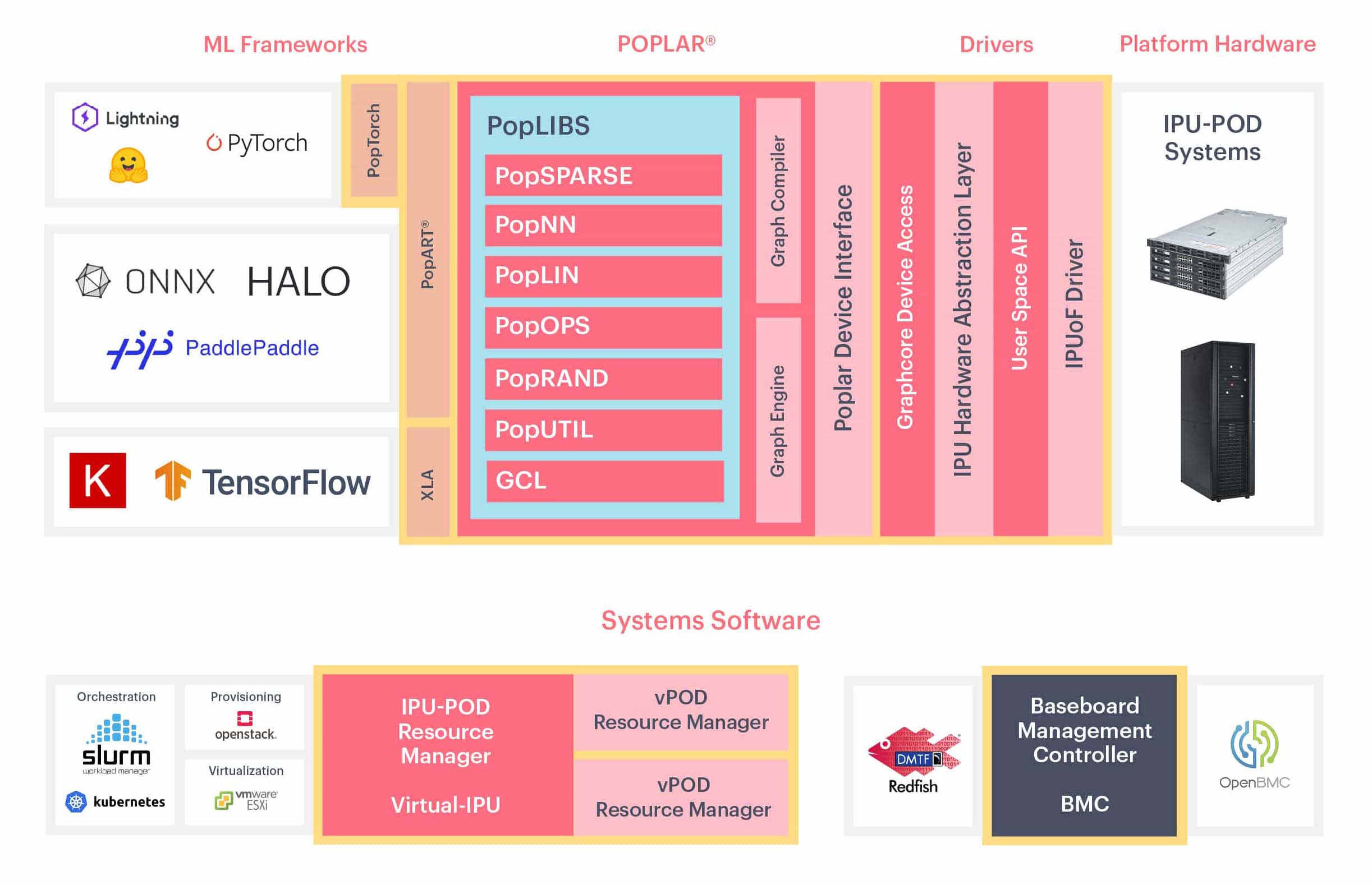
Graphcore's Poplar software supports standard ML frameworks including TensorFlow, PyTorch, ONNX and PaddlePaddle as well as industry standard converged infrastructure management tools so it’s easy to deploy, including Open BMC, Redfish, Docker containers, and orchestration with Slurm and Kubernetes.
Highly Secure Cloud Access for Every Industry
Cloud security means protecting a complex web of workloads consisting of hardware, applications, and data spread across edge, core, remote workforce, and cloud deployments. Cirrascale Cloud Services’ data centers and infrastructure are architected to protect your information, identities, applications, and devices.
Accessing Graphcloud is secure and easy. Cirrascale uses industry-standard link encryption and authentication methods such as IPsec and SSH to ensure the security of data during transmission. A multitiered set of defensive services are also used to strictly control network access. Your data remains safe throughout your time using our service. Once you opt to exit our service, our engineering operations team personally verifies that your data has been removed.
Multi-Cloud Support Through Megaport
Customers can utilize Megaport connectivity through Cirrascale and an AWS DirectConnect, Azure ExpressRoute, or Google Cloud Partner Interconnect to enable a seamless connection between a customer’s VPC at these hyperscalers and their Graphcloud instance.
This connection lets customers connect to any one of, or to a multiple of, the world’s leading hyperscalers and access best-of-breed services. Additionally, it enables customers to connect to multiple cloud regions from a single interconnection point with greater security and privacy than traditional networking solutions.
Graphcloud Pricing
Using a Graphcore Graphcloud instance with Cirrascale ensures no hidden fees with our flat-rate billing model. You pay one price without the worry of fluctuating bills like those at other providers. All pricing shown for PODs are per POD specified per month.
| IPU Instance | IPU Specs | Weekly Pricing | Monthly Pricing | Annual Pricing |
|---|---|---|---|---|
| Bow Pod 16 | 4x Bow-2000 | $3,250($19.35/hr*) |
$12,000($16.44/hr*) |
$9,600($13.15/hr*) |
| Bow Pod 64 | 16x Bow-2000 | $13,000($77.38/hr*) |
$48,000($65.75/hr*) |
$38,400($52.60/hr*) |
| Bow Pod 128 | 32x Bow-2000 | $26,000($154.76/hr*) |
$96,000($131.51/hr*) |
$76,800($105.21/hr*) |
| Bow Pod 256 | 64x Bow-2000 | $52,000($306.52/hr*) |
$192,000($263.01/hr*) |
$153,600($210.41/hr*) |
| Bow Pod 512 | 128x Bow-2000 | $104,000($619.05/hr*) |
$384,000($526.03/hr*) |
$307,200($420.82/hr*) |
| Bow Pod 1024 | 256x Bow-2000 | $208,000($1,238.10/hr*) |
$768,000($1,052.05/hr*) |
$614,400($841.64/hr*) |
| IPU-POD: Classic 16 | 4x IPU-M2000 | $2,437.50($14.51/hr*) |
$9,000($12.33/hr*) |
$7,200($9.86/hr*) |
| IPU-POD: Classic 64 | 16x IPU-M2000 | $9,750($58.04/hr*) |
$36,000($49.32/hr*) |
$28,800($39.45/hr*) |
| IPU-POD: Classic 128 | 32x IPU-M2000 | $19,500($116.07/hr*) |
$72,000($98.73/hr*) |
$57,600($78.90/hr*) |
| IPU-POD: Classic 256 | 64x IPU-M2000 | $39,000($232.14/hr*) |
$144,000($197.26/hr*) |
$115,200($157.81/hr*) |
| IPU-POD: Classic 512 | 128x IPU-M2000 | $78,000($464.29/hr*) |
$288,000($394.52/hr*) |
$230,400($315.62/hr*) |
| IPU-POD: Classic 1024 | 256x IPU-M2000 | $156,000($928.57/hr*) |
$576,000($789.04/hr*) |
$460,800($631.23/hr*) |
* Cirrascale Cloud Services does not provide servers by the hour. The "hourly equivalent" price is shown as a courtesy for comparison against vendors like AWS, Google Cloud, and Microsoft Azure.
High-Speed and Object Storage Offerings
Cirrascale has partnered with the industry’s top storage vendors to supply our customers with the absolute fastest storage options available. Connected with up to 100Gb Ethernet, our specialized NVMe hot-tier storage offerings deliver the performance needed to eliminate workflow bottlenecks.
| Type | Capacity | Price/GB/Month |
|---|---|---|
| NVMe Hot-Tier Storage | 50TB or Greater | $0.20 |
| Object Storage | Less Than 50TB | $0.04 |
| Object Storage | 50TB - 2PB | $0.02 |
| Object Storage | 2PB or Greater | $0.01 |
Additional Resources
Getting Started with Graphcloud
Get up and running fast using Graphcore IPUs and Poplar software with Graphcore's comprehensive "Getting Started" documentation.
Poplar SDK Analyst Report
Detailed technical white paper on the Poplar software stack from analyst Moor Insights & Strategy.
Access Graphcloud
Sign-up to access Graphcloud and experience scale-out performance of up to 1,024 Graphcore Bow IPUs as a secure monthly cloud service.


Gain Access to Graphcloud
If you are interested in gaining access to the Cirrascale Graphcloud IPU-POD instances, please fill our our sign-up form. Please completely fill out the form so that we can ensure an accurate review of your request.
Once received, we'll review you information and have one of our onboarding representatives give you a call to schedule your service.